This page was generated from docs/tutorials/rockpool-shd.ipynb.
Interactive online version:
![]()
🔊 Training an audio classification task using Torch 🔥
The examples so far are predominantly regression-based. Rockpool is designed for time-series tasks, such as audio processing. This tutorial provides a basic overview of how one can train Rockpool on a standard dataset that is more representative of real-world tasks. For this example we use the Spiking Heidelberg Datasets and Spiking Heidelberg Digits (SHD) specifically. SHD consists of 8156 samples of spoken digits between 0 and 9 in English and German by 12 different speakers, corresponding to 20 possible classes. Each sample has 700 channels and up to around a second of data.
Importing the SHD Dataset Using Tonic
The creators of the SHD dataset provide a tutorial implementation which details how to download the data and demonstrates a custom class to import the dataset. As-downloaded, the default format of the SHD dataset is HDF5 files. For simplicity, we use Tonic, a Python package which provides event-based vision and audio datasets and transformations. Tonic provides the ability to load the SHD dataset in just a few lines of code, as well as transform the input easily into a low-dimensional form. Make sure this is installed as per the Tonic webpage instructions before proceeding with this tutorial.
We can use Rockpool’s TSEvent class to visualise the data:
[1]:
# - Imports for loading data
import tonic
from tonic import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import torch
from rockpool.timeseries import TSEvent
try:
from rich import print
except ModuleNotFoundError:
pass
import sys
!{sys.executable} -m pip install --quiet matplotlib
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [12, 6]
download_dir='./data'
# - Download and import the training data. The transform ensures the data has a floating type
train_data = datasets.SHD(download_dir, train=True, transform=transforms.NumpyAsType(float))
train_dl = iter(DataLoader(train_data, drop_last=True, shuffle=False))
[2]:
# - Visualise Data
events, label = next(train_dl)
# Extract values for the first sample from the dataloader
times=events[0,:,0]
events=events[0,:,1]
# Create a TSEvent object corresponding to the first sample
spikes_ts = TSEvent(
times=times.numpy() * 1e-6,
channels=events.numpy(),
t_stop=(times.max()+1) * 1e-6
)
spikes_ts.plot()
plt.title(f'Encoded SHD Sample #1 (Class={label.item()})')
# plt.xlim((0, 1.1))
plt.ylim((0, 700))
plt.show()
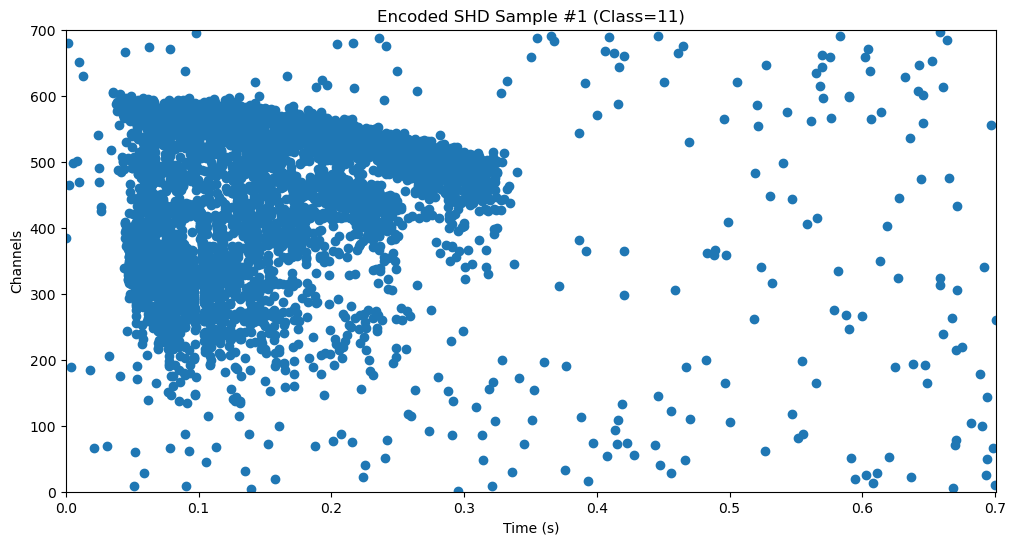
As we can see, a given sample consists of some number of events across 700 channels and some duration of time. 700 channels means a high-dimensional dataset, and so large training times and networks. For low-power applications, it is desirable to use lower dimensional input. Using Tonic, we can transform the input into a better format. We can rasterise the input to facilitate training. Note: the duration of each sample may be different, thus it is useful to pad samples to make them of uniform length. We define the following parameters. Initially, we will use an encoding dimension of 20, i.e., reduce 700 input channels to 20.
[3]:
shd_timestep = 1e-6
shd_channels = 700
net_channels = 20
net_dt = 10e-3
sample_T = 100
batch_size = 256
num_workers = 6
We now create a class to rasterise the input:
[4]:
class ToRaster():
def __init__(self, encoding_dim, sample_T = 100):
self.encoding_dim = encoding_dim
self.sample_T = sample_T
def __call__(self, events):
# tensor has dimensions (time_steps, encoding_dim)
tensor = np.zeros((events["t"].max()+1, self.encoding_dim), dtype=int)
np.add.at(tensor, (events["t"], events["x"]), 1)
return tensor[:self.sample_T,:]
Now we can define the transforms which we apply to the dataset to prepare it for training:
[5]:
transform = transforms.Compose([
transforms.Downsample(
time_factor=shd_timestep / net_dt,
spatial_factor=net_channels / shd_channels
),
ToRaster(net_channels, sample_T = sample_T),
torch.Tensor,
# transforms.ToFrame(
# sensor_size=(net_channels, 1, 1), time_window=100, include_incomplete=True
# ),
])
Reload the dataset with the applied transforms:
[6]:
# - Use a GPU if available for faster training
dev = "cuda:0" if torch.cuda.is_available() else "cpu"
device = torch.device(dev)
dataloader_kwargs = dict(
batch_size=128,
shuffle=True,
drop_last=True,
pin_memory=True,
collate_fn=tonic.collation.PadTensors(batch_first=True),
num_workers=8,
)
train_data = datasets.SHD(download_dir, train=True, transform=transform)
# disk_train_dataset = tonic.MemoryCachedDataset(
disk_train_dataset = tonic.DiskCachedDataset(
dataset=train_data,
# transform = torch.Tensor,lambda x: torch.tensor(x).to_sparse(),
cache_path=f"cache/{train_data.__class__.__name__}/train/{net_channels}/{net_dt}",
# target_transform=lambda x: torch.tensor(x),
reset_cache = True,
)
# device = device,
# )
train_dl = DataLoader(disk_train_dataset, **dataloader_kwargs)
tonic.collation.PadTensors(batch_first=True) performs padding to ensure a consistent sample length for each sample across all batches. ToRaster above indicates a maximum sample length of 100 points.
We can now visualise the first sample in its encoded form in the same way as before:
[7]:
events, label = disk_train_dataset[0]
# events = events.to_dense().cpu().numpy()
spikes_ts = TSEvent.from_raster(events.squeeze(), dt = net_dt, name = f'Encoded SHD Sample #1 (Class={label.item()})')
spikes_ts.plot()
plt.show()
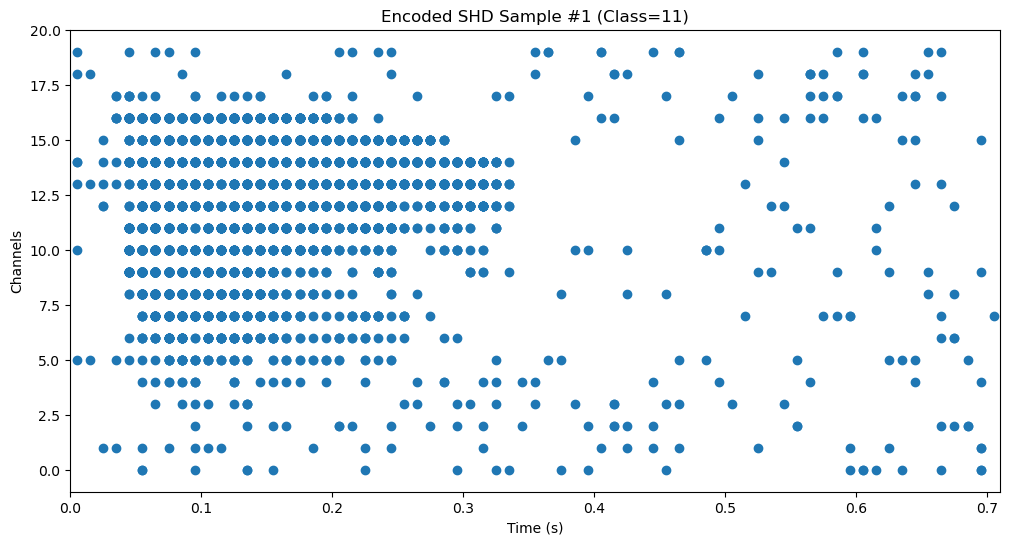
Now that our data is in the correct format, we can define our network. To begin, we use a simple network consisting of a linear layer, a leaky integrate-and-fire layer, another linear layer, and an exponential synapse output layer:
[8]:
from rockpool.nn.modules import LIFTorch, LinearTorch, ExpSynTorch, LIFExodus
from rockpool.nn.combinators import Sequential
from rockpool.parameters import Constant
# - Select a neuron model to use
from rockpool.utilities.backend_management import backend_available
NeuronModel = LIFExodus if backend_available('sinabs-exodus') and torch.cuda.is_available() else LIFTorch
# - Network Definition
def SimpleNet(Nin, Nhidden, Nout):
return Sequential(
LinearTorch((Nin, Nhidden), has_bias=False),
NeuronModel(Nhidden,
tau_mem=Constant(100e-3),
tau_syn=Constant(100e-3),
threshold=Constant(1.),
bias=Constant(0.),
dt=net_dt,
has_rec=False),
LinearTorch((Nhidden, Nout), has_bias = False),
ExpSynTorch(Nout, dt=net_dt, tau=Constant(5e-3))
)
Note, we use the Constant functionality here as, by default, all parameters in Rockpool are trainable. Keeping everything except the weights constant ensures fast training for the example. We can now define our network shape:
[9]:
# - Build a network
Nin = net_channels
Nhidden = 20
Nout = 20
torch.manual_seed(1234) # A manual seed ensures repeatability
net = SimpleNet(Nin, Nhidden, Nout).to(dev)
print(net)
/home/dylan/mina_hdd/miniconda3/envs/py38/lib/python3.8/site-packages/torch/cuda/__init__.py:497: UserWarning: Can't initialize NVML
warnings.warn("Can't initialize NVML")
TorchSequential with shape (20, 20) { LinearTorch '0_LinearTorch' with shape (20, 20) LIFTorch '1_LIFTorch' with shape (20, 20) LinearTorch '2_LinearTorch' with shape (20, 20) ExpSynTorch '3_ExpSynTorch' with shape (20,) }
We can test the network output makes sense here. Setting record=True as an argument in the network allows you to save the record dictionary of the network at each layer. Let’s pass the first sample to the network and see what happens:
[10]:
events, labels = next(iter(train_dl)) # Get a batch from the train dataloader
events = events.to_dense().to(device)
sample = events[0,:,:] # Get the first sample from the first batch
output, state, rec = net(sample, record=True) # Pass the first sample through the network
Here, we see the network returns three things: the network output, the current network state, and the record dictionary. The output is a 3D Tensor of shape: [batch_size*[times*[channels]]]. It may help to visualise this as a Tensor of size batch_size (256 here) which contains another tensor whose size is equal to the number of time steps (100 in this case). This tensor contains 100 1x20 tensors, with each element corresponding to the number of neurons in the ExpSynTorch layer. You may
have seen us index tensors already in this tutorial, e.g., in the sample = events[0,:,:] line above. Tensor indexing here works as follows: tensor_name[batch_item, timestep, channel]. For example, to access the fifth neuron at the second timestep in the eighth sample in the batch, one should type sample = events[8,1,5]. To select all channels, timesteps, or batch items, use :, e.g., to access all channels and timesteps in the first sample, type sample = events[0,:,:].
The network state gives us the output of each layer in the network for a given input. The record dictionary stores all states for a given batch. To improve training time and reduce memory overheads, you may wish to skip the record=True argument, however it can be invaluable for debugging if the network doesn’t behave as expected. For example, if the network does not appear to give any output, one can use the record dictionary to determine whether a specific layer is at fault.
Now that we understand what our network outputs, we can define our training process. As SHD is a classification task, we use CrossEntropyLoss as our loss function. We use Adam as our optimiser.
[11]:
from torch.optim import Adam
from torch.nn import CrossEntropyLoss
# - Get the optimiser functions
optimizer = Adam(net.parameters().astorch(), lr=1e-3)
# - Loss function
loss_fun = CrossEntropyLoss()
# - Record the loss values over training iterations
accuracy = []
loss_t = []
num_epochs = 500
We are now ready to build our training loop:
[12]:
# Import tqdm to visualise training progress
from tqdm.autonotebook import tqdm
# - Training Loop
with tqdm(range(num_epochs), unit = 'Epoch', desc = 'Training') as pbar:
for _ in pbar:
correct = 0
total_loss = 0
total = 0
temp_loss = 0
net.train()
for events, labels in train_dl:
events, labels = events.to(device), labels.to(device)
# events = events.to_dense()
optimizer.zero_grad()
output, _, _ = net(events)
sum = torch.cumsum(output, dim=1)
loss = loss_fun(sum[:,-1,:], labels)
loss.backward()
optimizer.step()
# Calculate the number of correct answers
predicted = torch.argmax(sum[:,-1,:], 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
this_loss = loss.item()
# - Keep track of the accuracy
this_accuracy = (correct/total)*100
accuracy.append(this_accuracy)
loss_t.append(this_loss)
pbar.set_postfix(Loss = f'{this_loss:.2f}', Accuracy = f'{this_accuracy:.0f}%')
print(f"Training Accuracy: {accuracy[-1]:.3f}%")
[ ]:
# - Plot the Training Loss
fig, ax = plt.subplots()
ax.plot(loss_t, color='blue')
ax.set_ylabel('CrossEntropy loss', color='blue')
ax.set_yscale('log')
ax.set_xlabel('Epochs')
ax2 = ax.twinx()
ax2.plot(accuracy, color='orange')
ax2.plot(ax2.get_xlim(), [100/20, 100/20], '--', color='orange')
ax2.set_ylabel('Accuracy (%)', color='orange')
ax2.set_yscale('linear')
plt.title('Rockpool SHD training loss and accuracy')
plt.show()
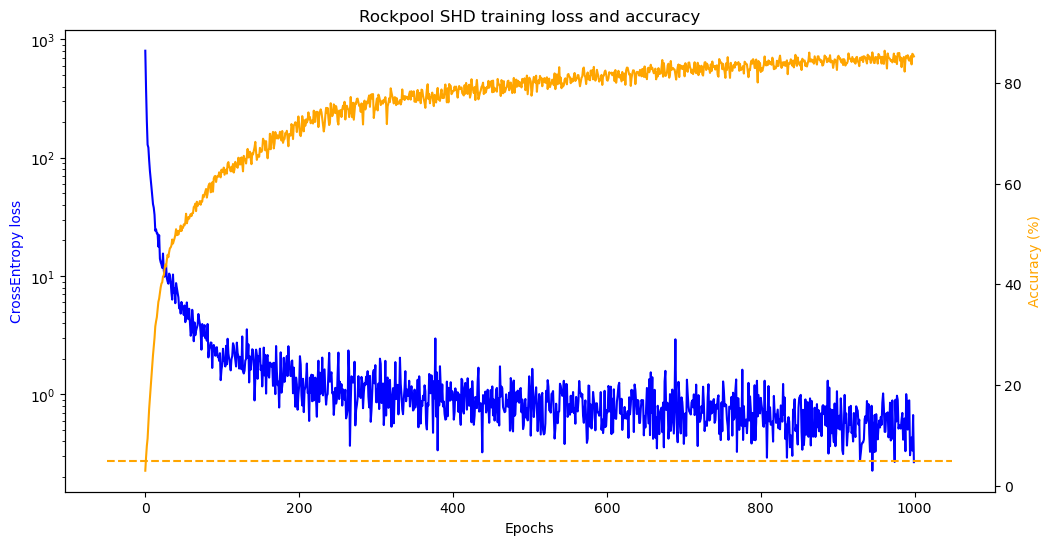
As the plot shows, our network successfully trains on the data! Feel free to experiment with different values for the learning rate, number of epochs and network parameters to see how the different parameters affect the network performance. Here we train for a limited number of epochs, but generally several hundred are required for convergence. You can re-run the cell above to train for longer periods.
The best values for the parameters will depend on the dataset. For example, here if tau_mem or tau_syn are too small (below about 0.02 for threshold = 1.), then the LIF layer will not fire and the network will not train. Depending on your application, it may be necessary to trial different values. As we note above, looking at the record dictionary can be very useful in figuring out what’s happening under the hood.
It’s worthwhile here to discuss the nature of the training loop. For a given sample or batch of samples that the network takes as input the network output is as described above, i.e., a tensor with the ExpSyn layer outputs for each batch and at each timestep. We want to integrate the output for each neuron over time, i.e., the synaptic current, isyn and pass this to the CrossEntropyLoss function. We do perform this integration by taking the cumulative sum of the synaptic currents for each
channel using sum = torch.cumsum(output, dim=1). The loss function expects a Tensor of size [batch_size*[channels]] and so we need to take the value for the last timestep, which we do by indexing sum[:,-1,:]. As we note above, the SHD dataset has 20 possible output classes. Our network’s 20 output neurons correspond to a class, and so our prediction is the specific neuron with the largest synaptic current. We can easily find this by taking the argmax of the output neurons at the last
timestep. This allows us to calculate the accuracy as above.
Let’s see how the network fares on data it hasn’t seen before. First we load the test data and transform it in the same way as for the training data:
[ ]:
test_data = datasets.SHD(download_dir, train=False, transform=transform)
test_dl = DataLoader(test_data, num_workers=num_workers, batch_size=batch_size,
collate_fn=tonic.collation.PadTensors(batch_first=True), drop_last=True, shuffle=False)
We can now build our test loop to see how the network performs on the validation set:
[ ]:
# - Test loop:
net.eval()
with torch.no_grad():
correct = 0
total = 0
total_loss = 0
for events, labels in test_dl:
events, labels = events.to(dev), labels.to(dev)
output, _, _ = net(torch.Tensor(events).float())
sum = torch.cumsum(output, dim=1)
predicted = torch.argmax(sum[:,-1,:], 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy_test = (correct/total)*100
print(f"Test Accuracy: {accuracy_test:.3f}%")
Test Accuracy: 66.748%
As we see, the network doesn’t perform as well on the test data, but by playing around with the different parameters, as well as introducing techniques such as Dropout or regularisation, one should be able to obtain good performance. The authors provide a leaderboard for the best-performing networks, which, at the time of writing, has 48.1% in 6th place, and 91.1% in first place.