This page was generated from docs/tutorials/jax_lif_sgd.ipynb.
Interactive online version:
![]()
⚡️ Training a spiking network with Jax
This tutorial demonstrates using Rockpool and a Jax-accelerated LIF feed-forward neuron layer to perform gradient descent training of all network parameters. The result is a trained spiking layer which can generate a pre-defined signal from a noisy spiking input.
Requirements and housekeeping
This example requires the Rockpool package from SynSense, as well as jax and its dependencies.
[1]:
import jax
[2]:
# - Switch off warnings
import warnings
warnings.filterwarnings("ignore")
# - Rockpool imports
from rockpool import TSEvent, TSContinuous
from rockpool.nn.modules import LIFJax, LinearJax, ExpSynJax
from rockpool.nn.modules.jax.jax_lif_ode import LIFODEJax
from rockpool.nn.combinators import Sequential
from rockpool.parameters import Constant
# - Typing
from typing import Callable, Dict, Tuple
import types
# - Numpy
import numpy as np
import copy
# - Pretty printing
try:
from rich import print
except:
pass
# TQDM
from tqdm.autonotebook import tqdm
# - Plotting imports and config
import sys
!{sys.executable} -m pip install --quiet matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams["figure.figsize"] = [12, 4]
plt.rcParams["figure.dpi"] = 300
Signal generation from frozen noise task
We will use a single feed-forward layer of spiking neurons to convert a chosen pattern of random input spikes over time, into a pre-defined temporal signal with complex dynamics.
The network architecture is strictly feedforward, but the spiking neurons nevertheless contain temporal dynamics in their synaptic and membrane signals, with explicit time constants.
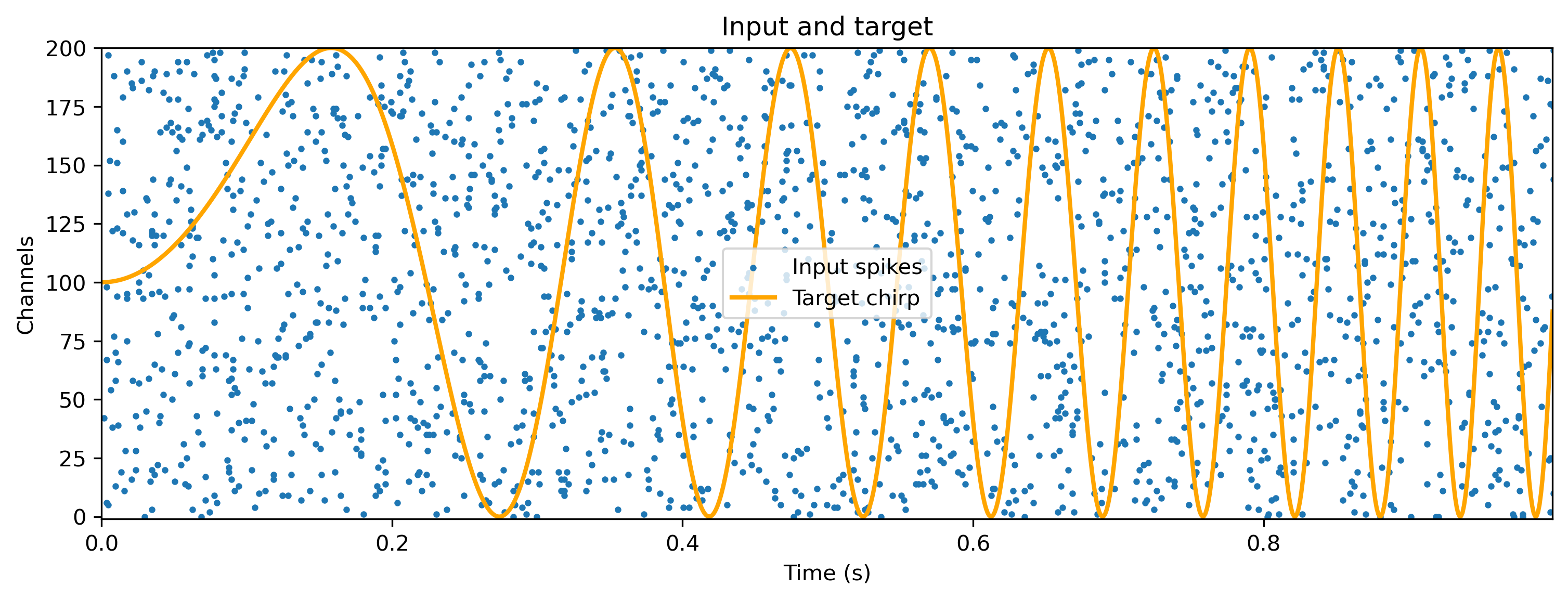
Some number of input channels Nin will contain independent Poisson spikes at some rate spiking_prob/dt. A single output channel should generate a chirp signal with increasing frequency, up to a maximum of chirp_freq_factor. You can play with these parameters below.
[3]:
# - Define input and target
Nin = 200
dt = 1e-3
chirp_freq_factor = 10
dur_input = 1000e-3
# - Generate a time base
T = int(np.round(dur_input / dt))
timebase = np.linspace(0, (T - 1) * dt, T)
# - Generate a chirp signal as a target
chirp = np.atleast_2d(np.sin(timebase * 2 * np.pi * (timebase * chirp_freq_factor))).T
target_ts = TSContinuous(timebase, chirp, periodic=True, name="Target chirp")
# - Generate a Poisson frozen random spike train
spiking_prob = 0.01
input_sp_raster = np.random.rand(T, Nin) < spiking_prob
input_sp_ts = TSEvent.from_raster(
input_sp_raster, name="Input spikes", periodic=True, dt=dt
)
# - Plot the input and target signals
plt.figure()
input_sp_ts.plot(s=4)
(target_ts * Nin / 2 + Nin / 2).plot(color="orange", lw=2)
plt.legend()
plt.title("Input and target");
LIF neuron
The spiking neuron we will use is a leaky integrate-and-fire spiking neuron (“LIF” neuron). This neuron recevies input spike trains \(S_{in}(t) = \sum_j\delta(t-t_j)\), which are integrated via weighted exponential synapses. Synaptic currents are then integrated into a neuron state (“membrane potential”) \(V_{mem}\).
The neuron obeys the dynamics
Where \(\tau_{mem}\) and \(\tau_{syn}\) are membrane and synaptic time constants; \(I_{bias}\) is a constant bias current for each neuron; \(\sigma\zeta(t)\) is a white noise process with std. dev. \(\sigma\).
Output spikes are generated when \(V_{mem}\) crosses the firing threshold \(V_{th} = 0\). This process generates a spike train \(S(t)\) as a series of delta functions, and causes a subtractive reset of \(V_{mem}\):
The analog output signal is generated using a surrogate
The output of the network \(o(t)\) is therefore given by
For more detail, see the documentation for the Jax module LIFJax.
Build a network
The network architecture is a single feedforward layer, with weighted spiking inputs and outputs. Spiking is generated via a function that provides a surrogate gradient in the backwards pass. This permits propagation of an error gradient through the layer, making gradient-descent training possible.
For this regression task we will also use an exponential synapse layer to perfprm temporal smoothing of the output. Regressing to a smooth signal is much easier with a continuous output signal, than using the spike deltas alone.
[4]:
# - Network size
N = 50
Nout = 1
input_scale = 1.
[5]:
# - Generate a network using the sequential combinator
modFFwd = Sequential(
LinearJax((Nin, N)),
LIFJax(N, dt=dt),
ExpSynJax(N),
LinearJax((N, Nout)),
)
print(modFFwd)
JaxSequential with shape (200, 1) { LinearJax '0_LinearJax' with shape (200, 50) LIFJax '1_LIFJax' with shape (50, 50) ExpSynJax '2_ExpSynJax' with shape (50,) LinearJax '3_LinearJax' with shape (50, 1) }
Simulate initial state of network
If we simulate the untrained network with our random input spikes, we don’t expect anything sensible to come out. Let’s do this, and take a look at how the network behaves.
[6]:
# - Randomise the network state
modFFwd.reset_state()
# - Evolve with the frozen noise spiking input
tsOutput, new_state, record_dict = modFFwd(input_sp_raster * input_scale, record=True)
# - Plot the analog output
plt.figure()
plt.plot(tsOutput[0])
[6]:
[<matplotlib.lines.Line2D at 0x3186ab730>]
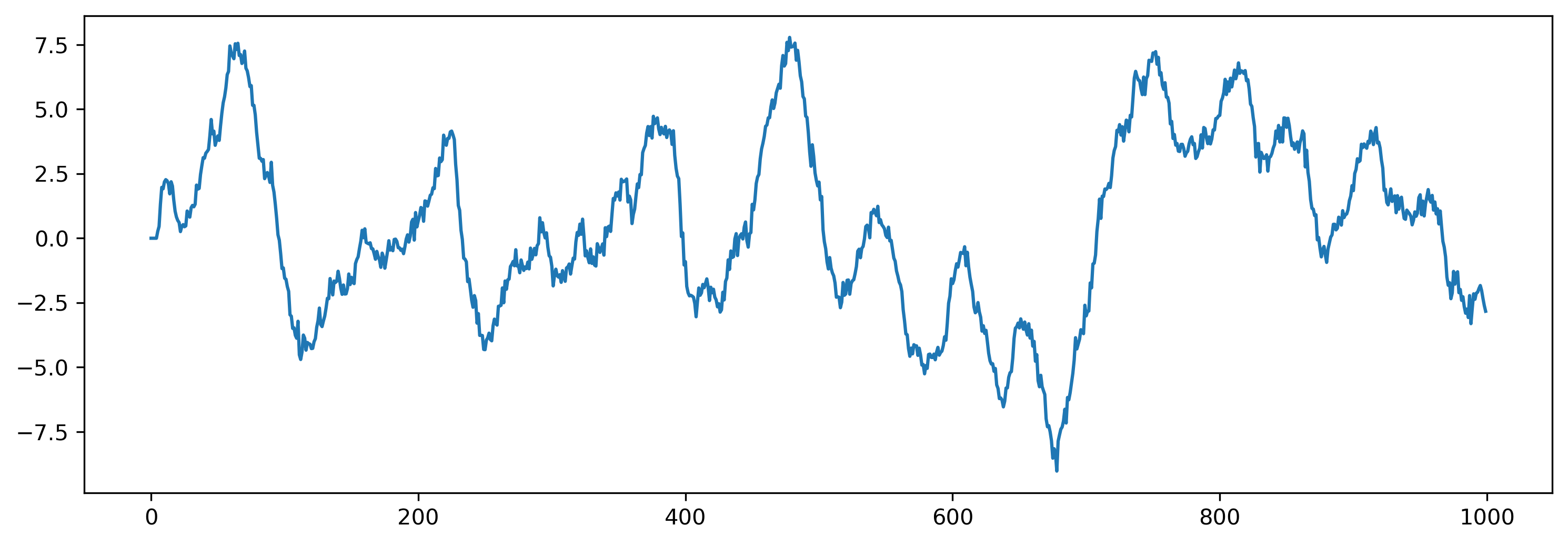
We can also examine the internal state of the network, by interrogating record_dict:
[7]:
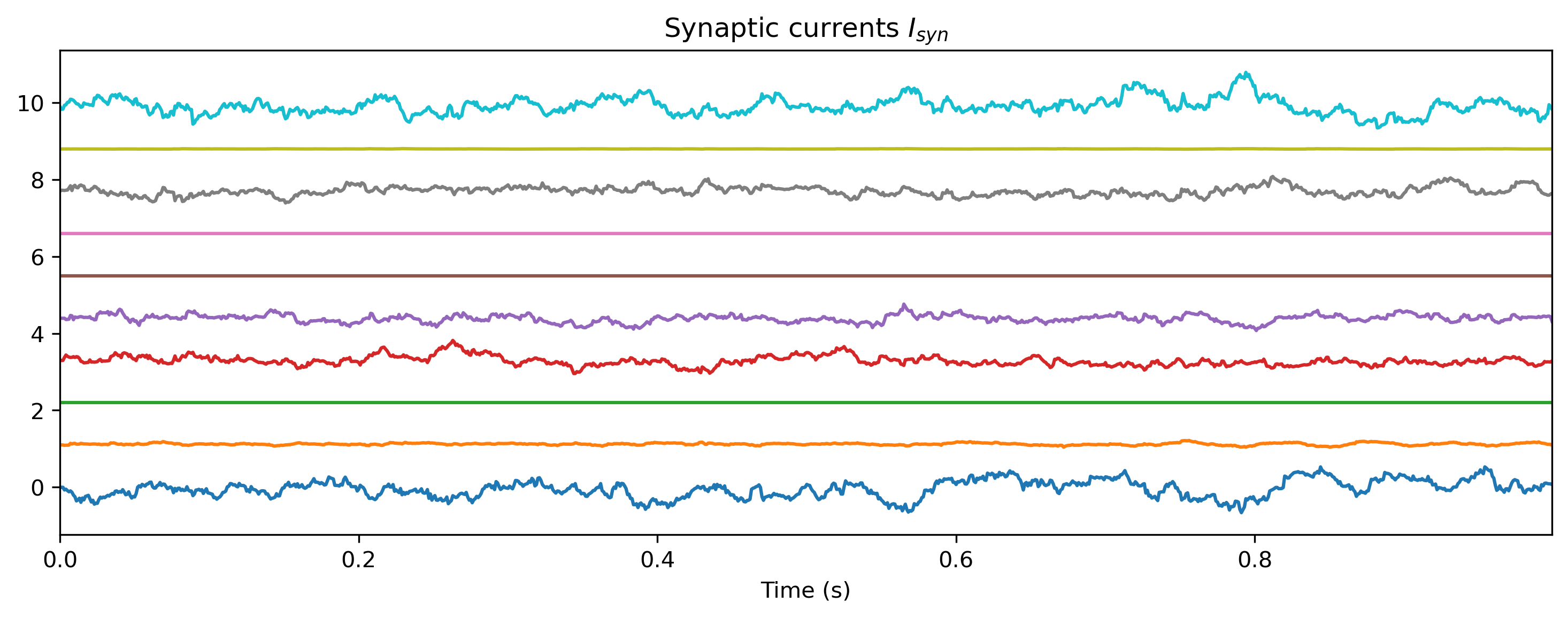
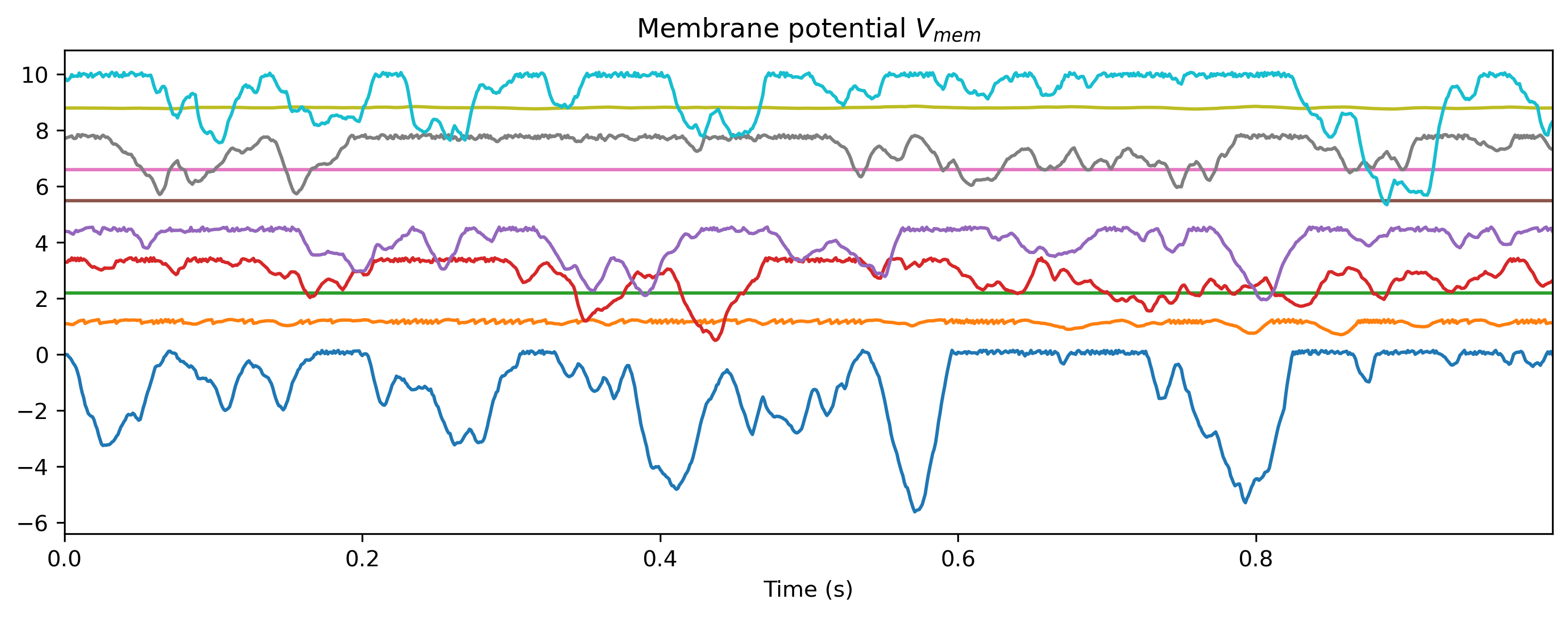
# - Make a function that converts ``record_dict``
def plot_record_dict(rd):
Isyn_ts = TSContinuous.from_clocked(
rd["1_LIFJax"]["isyn"][0, :, :, 0], dt, name="Synaptic currents $I_{syn}$"
)
Vmem_ts = TSContinuous.from_clocked(
rd["1_LIFJax"]["vmem"][0], dt, name="Membrane potential $V_{mem}$"
)
spikes_ts = TSEvent.from_raster(
rd["1_LIFJax"]["spikes"][0], dt, name="LIF layer spikes"
)
# - Plot the internal activity of selected neurons
plt.figure()
Isyn_ts.plot(stagger=1.1, skip=5)
plt.figure()
Vmem_ts.plot(stagger=1.1, skip=5)
plt.figure()
spikes_ts.plot(s=4)
plot_record_dict(record_dict)
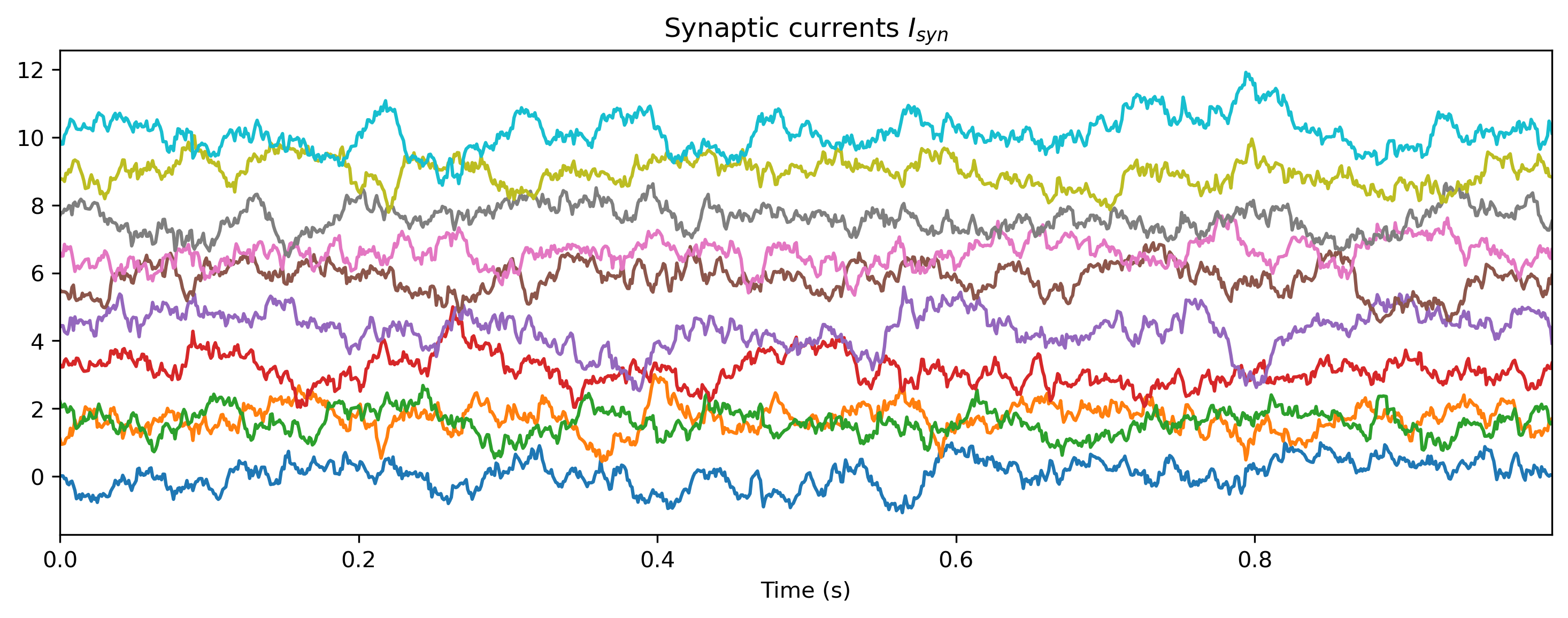
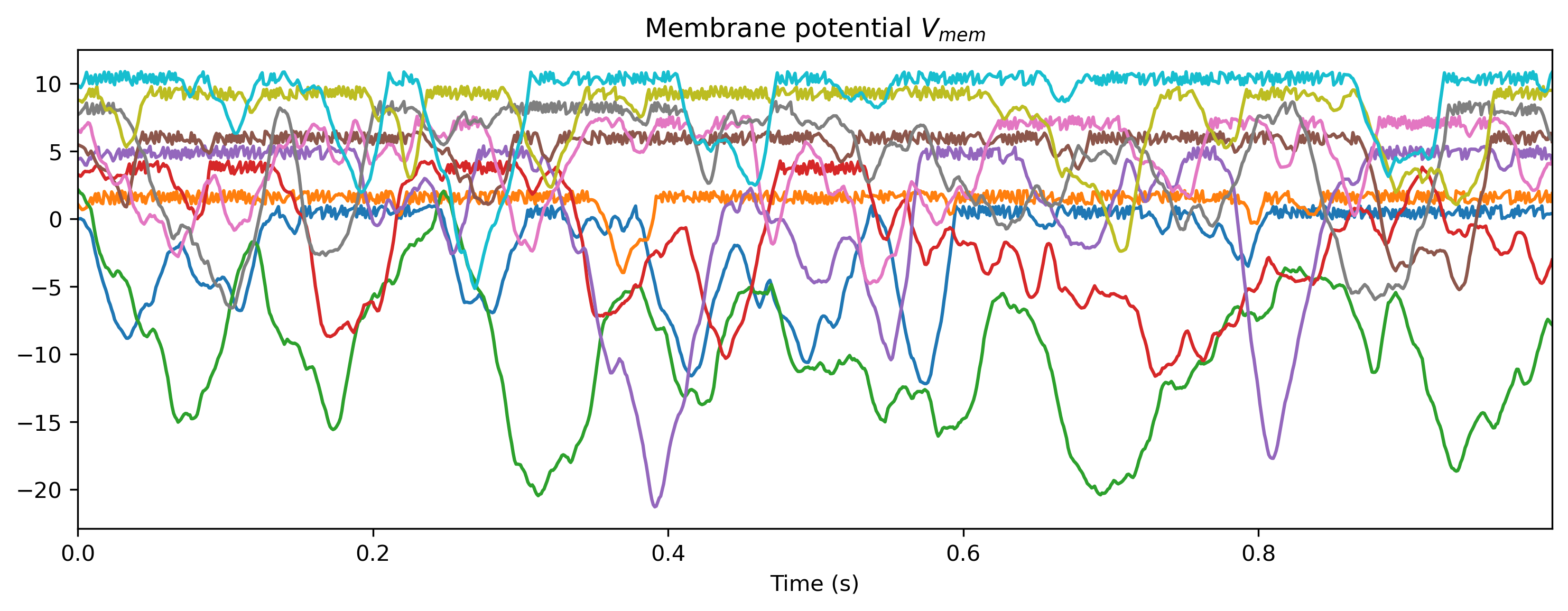

Training the network
In order to train the network we need to define a loss function to optimise. This function accepts a set of parameters, the network, the inputs and target for a trial, and computes an error (“loss”) for the trial. The loss computed by comparing the network output to the target using mean-squared error.
Usually you would add regularisation terms to the loss function, to make sure parameters don’t grow too large; to encourage low firing rates; etc. Generally you would want to also place bounds on the time constants, to prevent them becoming too small and causing numerical instability. See 🏃🏽♀️ Training a Rockpool network with Jax for more information.
[8]:
# - Import the convenience functions
from rockpool.training.jax_loss import bounds_cost, make_bounds, bounds_clip
# - Generate a set of pre-configured bounds
lower_bounds, upper_bounds = make_bounds(modFFwd.parameters())
print("lower_bounds: ", lower_bounds, "upper_bounds: ", upper_bounds)
lower_bounds: { '0_LinearJax': {'weight': -inf}, '1_LIFJax': {'bias': -inf, 'tau_mem': -inf, 'tau_syn': -inf, 'threshold': -inf}, '2_ExpSynJax': {'tau': -inf}, '3_LinearJax': {'weight': -inf} } upper_bounds: { '0_LinearJax': {'weight': inf}, '1_LIFJax': {'bias': inf, 'tau_mem': inf, 'tau_syn': inf, 'threshold': inf}, '2_ExpSynJax': {'tau': inf}, '3_LinearJax': {'weight': inf} }
[9]:
# - Impose a lower bound for the time constants
lower_bounds["1_LIFJax"]["tau_syn"] = 11 * dt
lower_bounds["1_LIFJax"]["tau_mem"] = 11 * dt
lower_bounds['1_LIFJax']['threshold'] = 0.1
lower_bounds["2_ExpSynJax"]["tau"] = 11 * dt
[10]:
print("lower_bounds:", lower_bounds)
lower_bounds: { '0_LinearJax': {'weight': -inf}, '1_LIFJax': {'bias': -inf, 'tau_mem': 0.011, 'tau_syn': 0.011, 'threshold': 0.1}, '2_ExpSynJax': {'tau': 0.011}, '3_LinearJax': {'weight': -inf} }
[11]:
import rockpool.training.jax_loss as l
import jax.numpy as jnp
# - Define a loss function
@jax.jit
def losses(params, net, input, target):
# - Reset the network state
net = net.reset_state()
# - Clip the parameters to bounds
params_clip = bounds_clip(params, lower_bounds, upper_bounds)
# - Apply the parameters
net = net.set_attributes(params_clip)
# - Evolve the network
output, _, states = net(input, record=True)
# - Calculate parameter bounds
bounds = bounds_cost(params, lower_bounds, upper_bounds)
# - Add an L2 norm to the parameters
l2 = l.l2sqr_norm(params)
# - Add cost to states
act_sum = 0.#np.mean(states['1_LIFJax']['isyn']**2)
# - Add cost to output
out_sum = np.mean(output**2)
# - Return the loss
return jnp.array([l.mse(output, target), bounds / 10, 100. * l2, act_sum * 10., out_sum / 100.])
def loss(params, net, input, target):
return losses(params, net, input, target).sum()
Below we define a training loop that uses a gradient-descent optimisation algorithm (“Adam”, provided by Jax) to iteratively optimise the network parameters. We keep track of the loss value for each iteration for later visualisation.
[12]:
# - Useful imports
from tqdm.autonotebook import tqdm
from copy import deepcopy
from itertools import count
# -- Import an optimiser to use and initalise it
import jax
from jax.example_libraries.optimizers import adam
# - Get the optimiser functions
init_fun, update_fun, get_params = adam(1e-4)
# - Initialise the optimiser with the initial parameters
params0 = copy.deepcopy(modFFwd.parameters())
opt_state = init_fun(modFFwd.parameters())
# - Get a compiled value-and-gradient function
loss_vgf = jax.jit(jax.value_and_grad(loss))
loss_gf = jax.jit(jax.grad(loss))
loss_f = jax.jit(loss)
# - Compile the optimiser update function
update_fun = jax.jit(update_fun)
# - Record the loss values over training iterations
loss_t = []
grad_t = []
losses_t = []
num_epochs = 10000
[13]:
# Test loss function
loss_gf(params0, modFFwd, input_sp_raster * input_scale, chirp);
loss_f(params0, modFFwd, input_sp_raster * input_scale, chirp);
loss_vgf(params0, modFFwd, input_sp_raster * input_scale, chirp);
[14]:
# - Loop over iterations
i_trial = count()
for _ in tqdm(range(num_epochs)):
# - Get parameters for this iteration
params = get_params(opt_state)
# - Get the loss value and gradients for this iteration
loss_val, grads = loss_vgf(params, modFFwd, input_sp_raster * input_scale, chirp)
losses_t.append(losses(params, modFFwd, input_sp_raster * input_scale, chirp))
# - Update the optimiser
opt_state = update_fun(next(i_trial), grads, opt_state)
# - Keep track of the loss
loss_t.append(loss_val)
losses_t.append(losses(params, modFFwd, input_sp_raster * input_scale, chirp))
[15]:
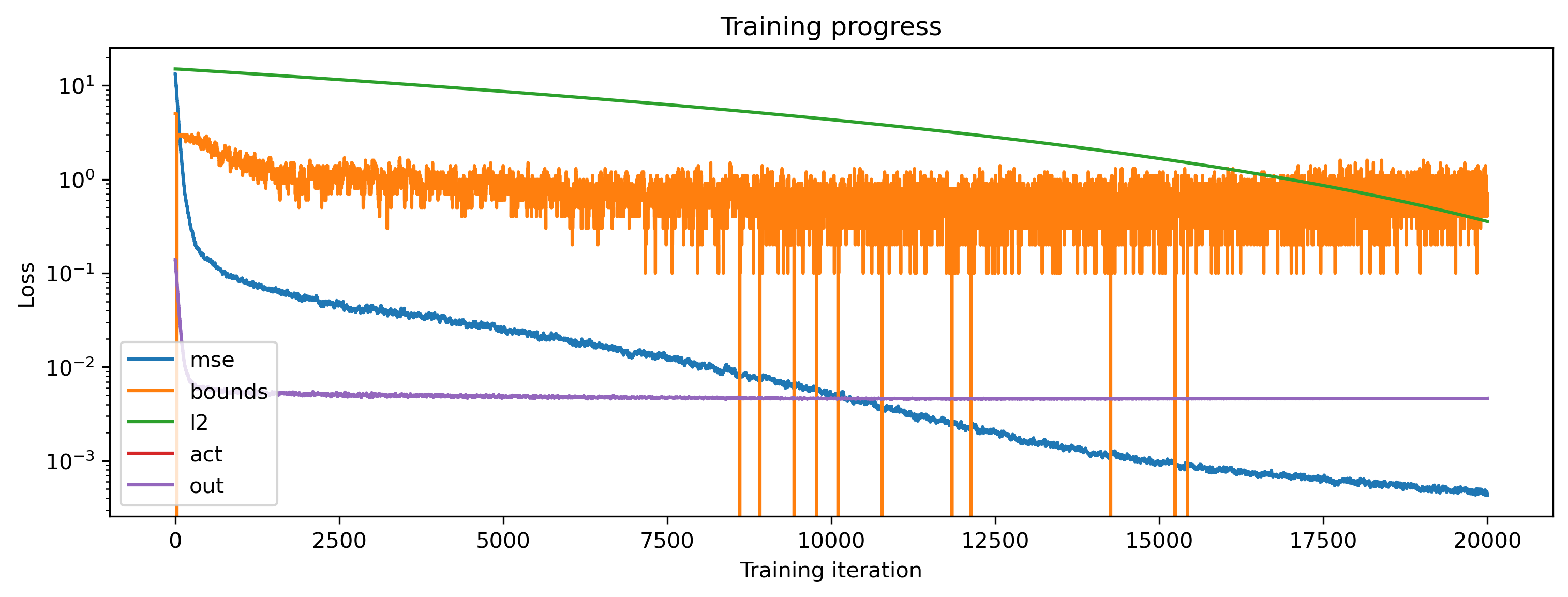
# - Plot the loss
plt.figure()
plt.plot(losses_t)
plt.yscale("log")
plt.ylabel("Loss")
plt.xlabel("Training iteration")
plt.title("Training progress");
plt.legend(['mse', 'bounds', 'l2', 'act', 'out'])
[15]:
<matplotlib.legend.Legend at 0x318b4dac0>
Plot the ouput of the trained network
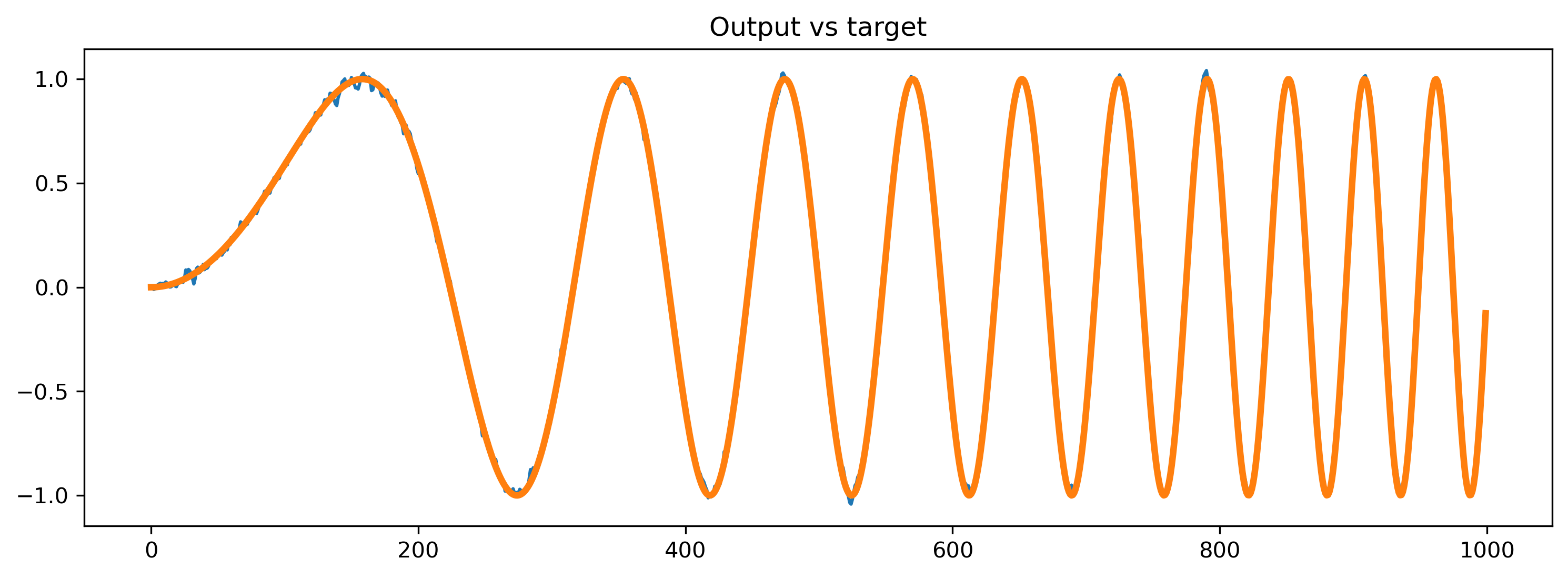
The MSE loss decreased — so far, so good. But what has the network learned?
[16]:
# - Simulate with trained parameters
modFFwd = modFFwd.set_attributes(get_params(opt_state))
modFFwd = modFFwd.reset_state()
output_ts, _, record_dict = modFFwd(input_sp_raster * input_scale)
# - Compare the output to the target
plt.plot(output_ts[0])
plt.plot(chirp, lw=3)
plt.title("Output vs target")
# - Plot the internal state of selected neurons
plot_record_dict(record_dict)

Plot the network parameters
Let’s see how much the network parameters changed. Since the initial parameter set was random, we’ll plot the difference between the trained and initial parameters \(\theta^* - \theta\).
[17]:
modIn = modFFwd[0]
modLIF = modFFwd[1]
modOut = modFFwd[3]
[18]:
# - Plot the change in input weights
plt.figure()
w_diff = modIn.weight - params0["0_LinearJax"]["weight"]
lim = np.max(np.abs(w_diff))
plt.imshow(w_diff, aspect="auto")
plt.title("Input weight change $w^*_{in}-w_{in}$")
plt.clim([-lim, lim])
plt.set_cmap("PuOr")
# - Plot the change in output weights
plt.figure()
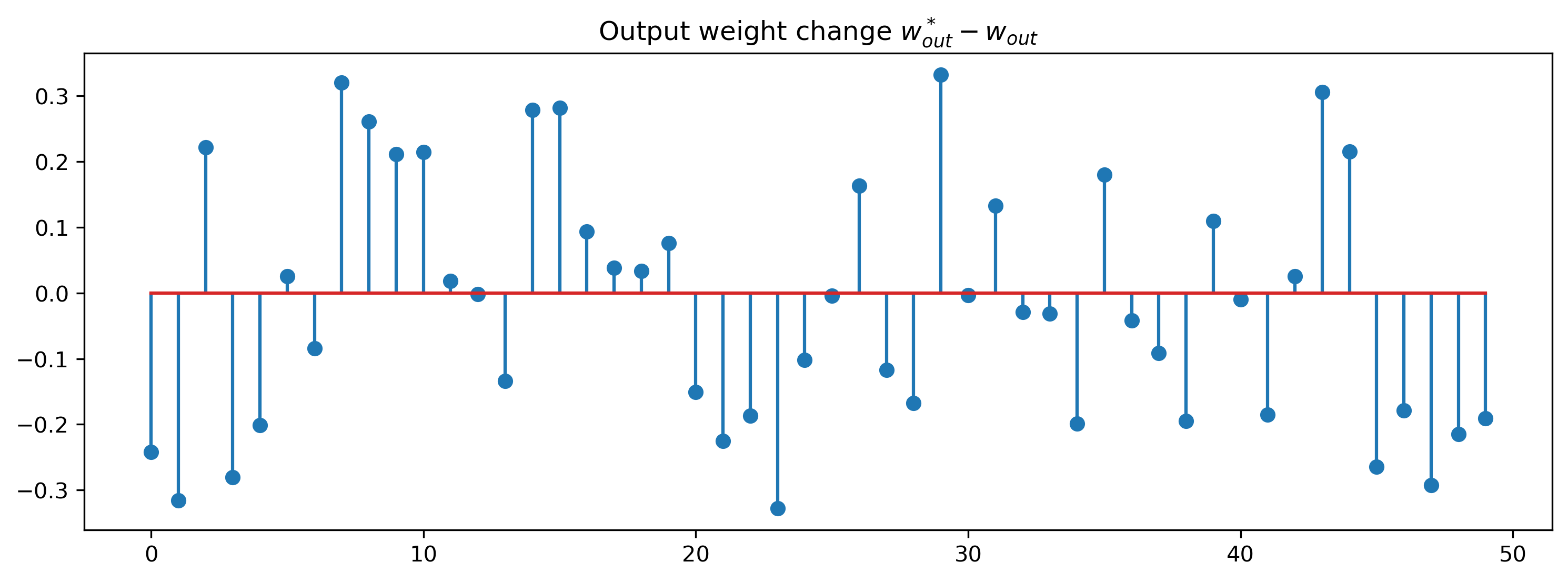
plt.stem(modOut.weight - params0["3_LinearJax"]["weight"])
plt.title("Output weight change $w^*_{out}-w_{out}$")
# - Plot the distribution of final time constants
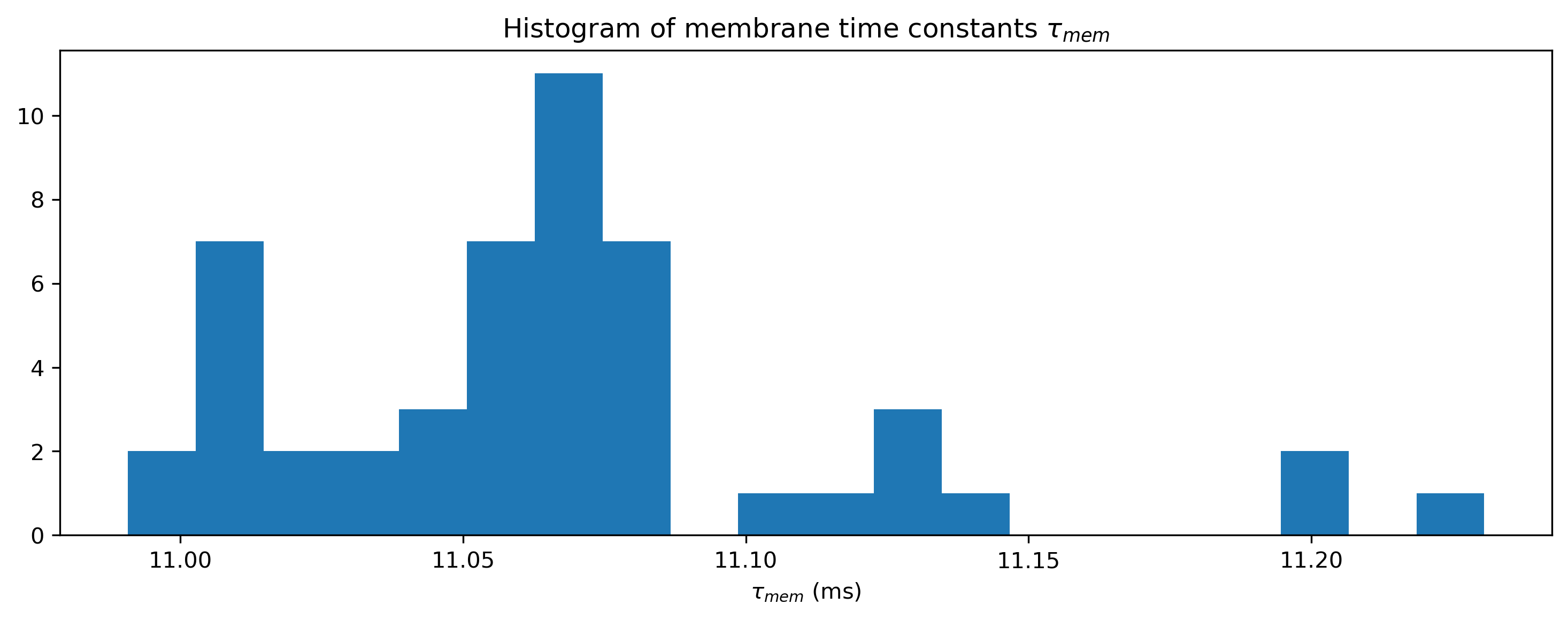
plt.figure()
plt.hist(np.array(modLIF.tau_mem.flatten()) * 1e3, 20)
plt.xlabel("$\\tau_{mem}$ (ms)")
plt.title("Histogram of membrane time constants $\\tau_{mem}$")
plt.figure()
plt.hist(np.array(modLIF.tau_syn.flatten()) * 1e3, 20)
plt.xlabel("$\\tau_{syn}$ (ms)")
plt.title("Histogram of synaptic time constants $\\tau_{syn}$")
# - Plot the distribution of final biases
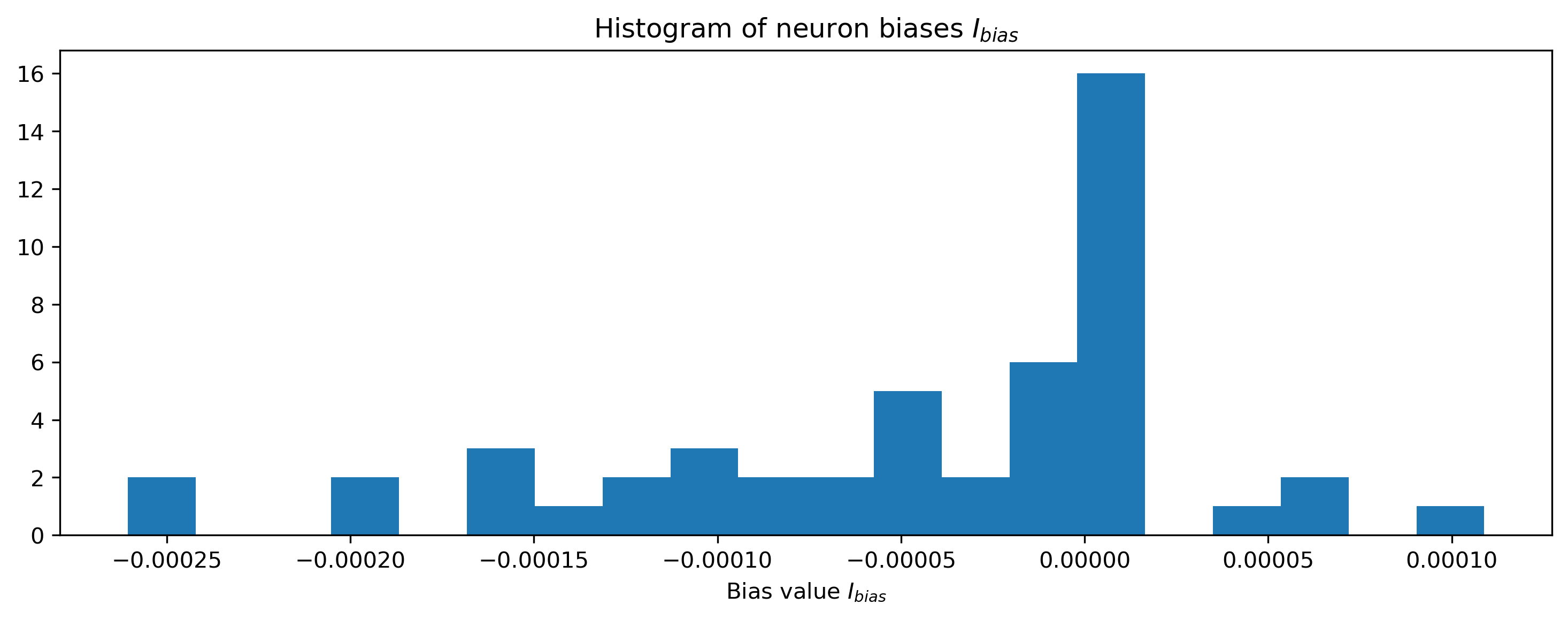
plt.figure()
plt.hist(np.array(modLIF.bias.flatten()), 20)
plt.xlabel("Bias value $I_{bias}$")
plt.title("Histogram of neuron biases $I_{bias}$");


The power of automatic differentiation is that almost for free, we get to optimise not just the weights, but all time constants and biases simultaneously. And we didn’t have to compute the gradients by hand!
As a sanity check, let’s see how the trained network responds if we give it a different random noise input.
[19]:
spiking_prob = 0.01
sp_rand_ts = np.random.rand(T, Nin) < spiking_prob
[20]:
# - Simulate with trained parameters
modFFwd = modFFwd.set_attributes(get_params(opt_state))
modFFwd = modFFwd.reset_state()
output_ts, _, record_dict = modFFwd(sp_rand_ts * input_scale)
# - Compare the output to the target
plt.plot(output_ts[0])
plt.plot(chirp, lw=3)
plt.title("Output vs target")
# - Plot the internal state of selected neurons
plot_record_dict(record_dict)
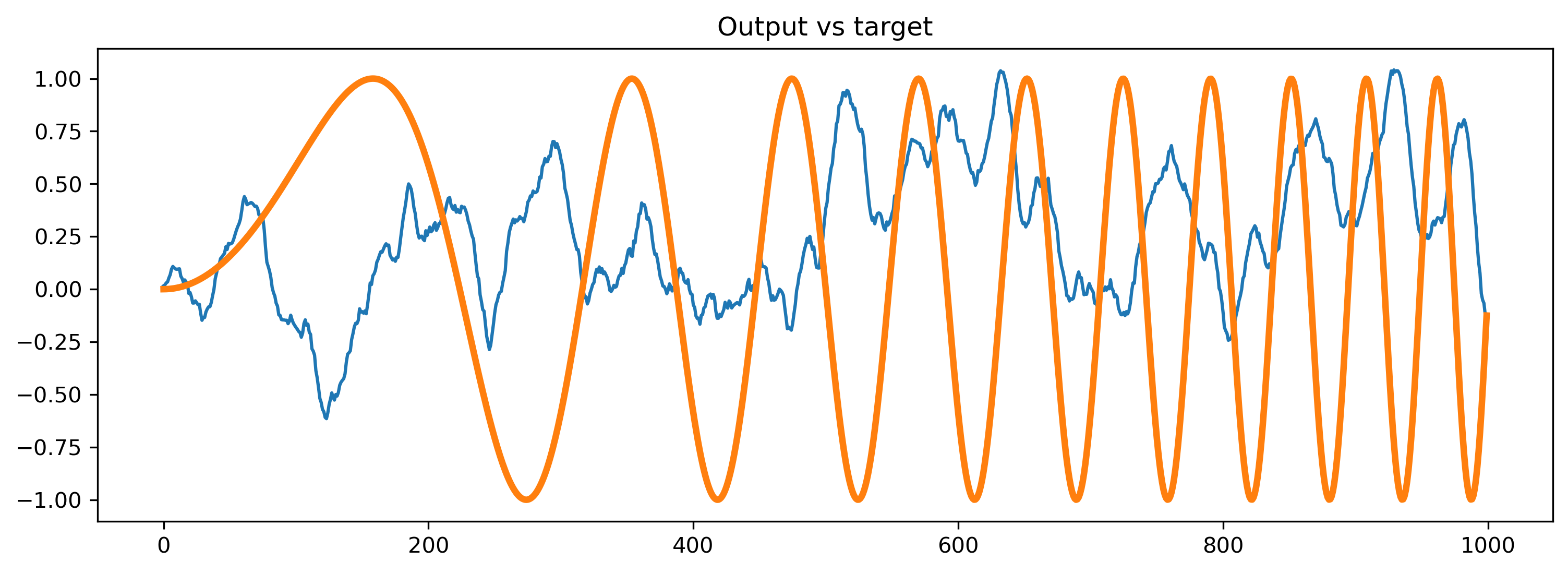
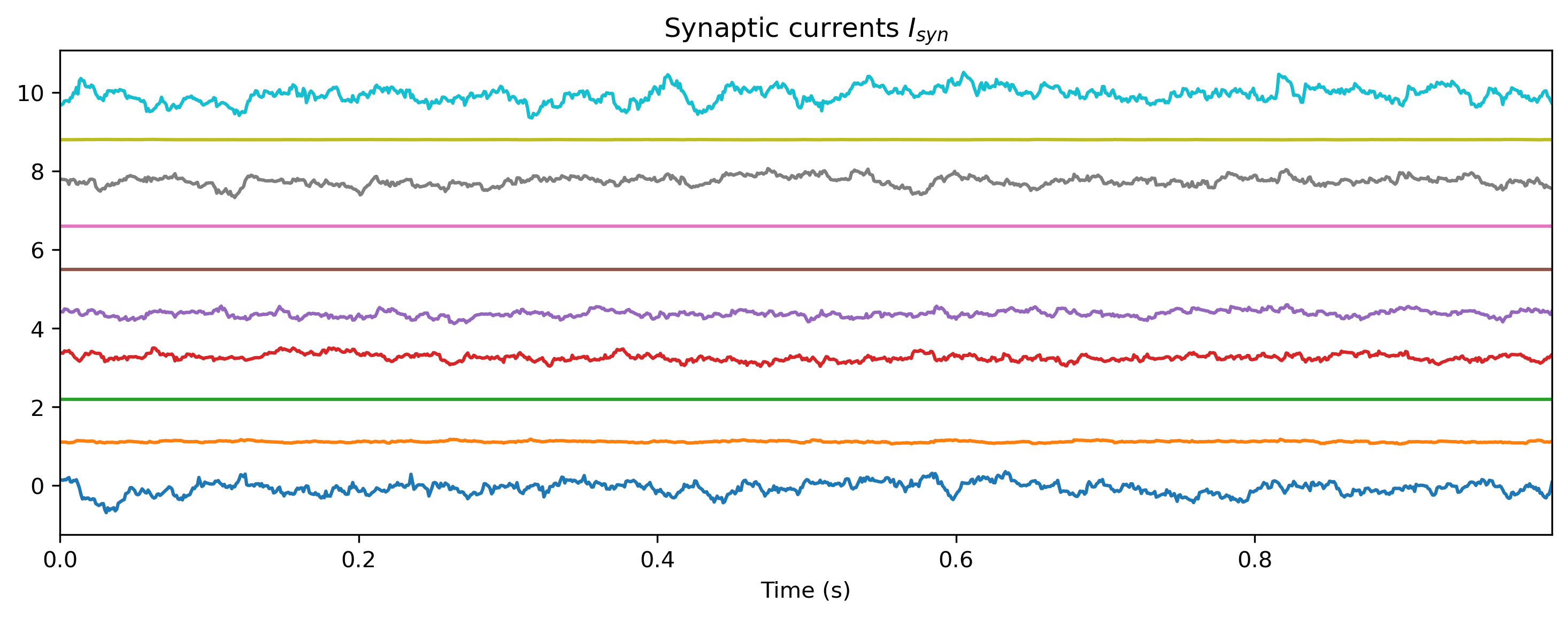
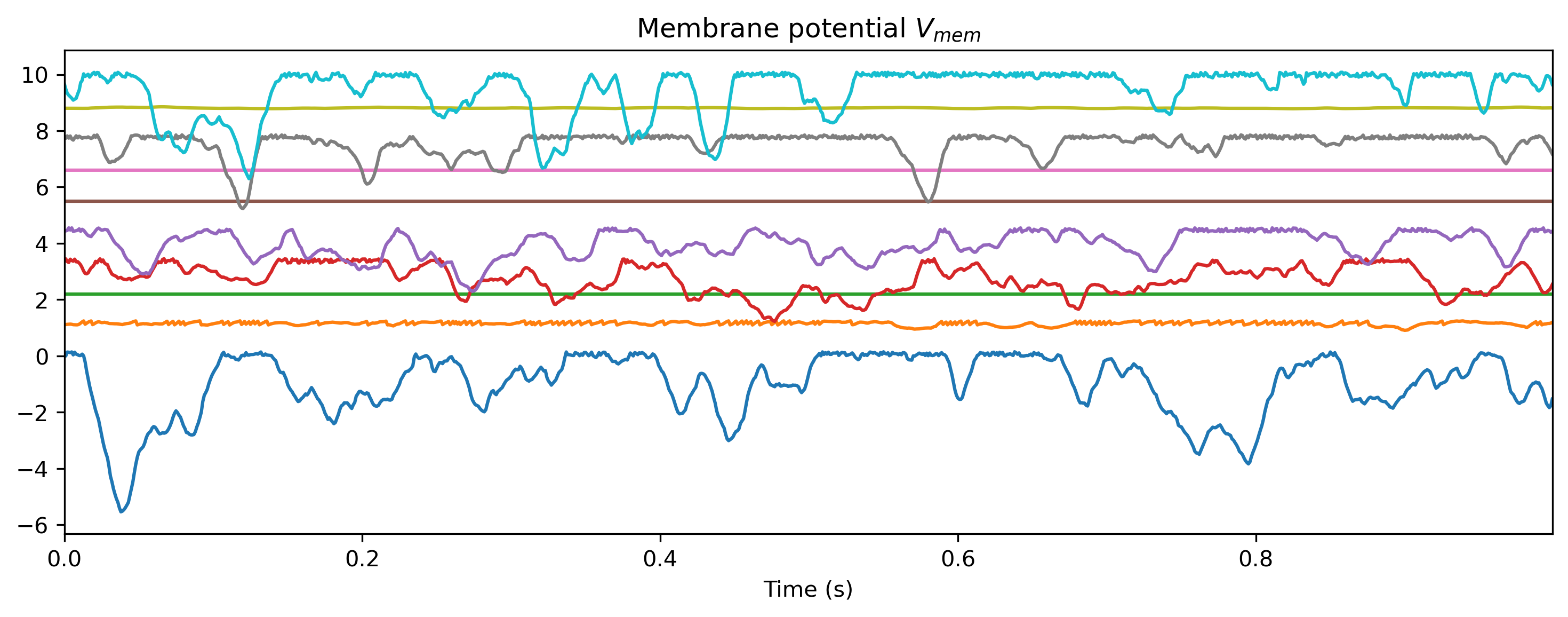

As expected, the network doesn’t do anything sensible with data it has never seen.
Summary
This approach can be used identically to train recurrent spiking networks, as well as multi-layer (i.e. deep) networks.