This page was generated from docs/devices/xylo-a3/AFESim3_as_transform.ipynb.
Interactive online version:
![]()
Using AFESim as an audio transform
Rockpool contains a simulation of the Audio Front End (AFE) of XyloAudio 3, which is used as a pre-processing step to convert audio signals to spike trains. The converted version of audio can be used in the following scenarios:
As a training sample to train an SNN model in Rockpool
As a test sample to test a model on the XyloAudio 3 SNN core for debugging purposes. This is done by bypassing the microphone and AFE in the HDK. See the related tutorial for more information.
In this tutorial, we will refer to the AFE simulator in XyloAudio 3 as AFESim3 and will go through an example of how to configure and use AFESim3 as an audio transform for a train or test pipeline.
There are two main modes in the AFESim3 module in Rockpool:
-
This mode of AFESim3 is independent of the microphone type. It bypasses the microphone path and passes an external audio (14-bit QUANTIZED signal) into the filterbank and divisive normalization module
-
In this mode, audio samples are passed through a preprocessing chain composed of PDM microphone model, filter bank and divisive normalization module
Using AFESimExternal is recommended for developing applications, while AFESimPDM is more suitable for advanced debugging tasks.
AFESimExternal
As illustrated in the diagram below, AFESimExternal receives input audio as an array, resamples and quantizes it to 14-bit format, and passes it to the filter bank (which covers 16 frequency bands between 100 Hz and 17 KHz).
Depending on the mode selected for spike_gen_mode, fixed or adaptive thresholds will be applied to filter output channels to generate a spike train. spike_gen_mode is by default set to 'divisive_norm', and changing it and related parameters (low_pass_averaging_window, rate_scale_factor, dn_EPS) is not recommended.
The Divisive Normalization (DN) module regulates the noise sensitivity of different frequency bands of the filter bank by applying adaptive thresholds.
If the average power of a filter in a specific time window is less than \(\epsilon\), that filter’s threshold will be adapted to generate fewer spikes.
The user can deactivate Divisive Normalization only for debugging purposes by choosing spike_gen_mode = 'threshold' and passing fixed_threshold_vec.
The spike train is rasterized with a given dt, which should the time step used in your SNN model.
[1]:
import warnings
from IPython.display import Image
warnings.filterwarnings("ignore")
Image("figures/afesim_external.png")
[1]:
The following transform can convert audio: np.ndarray samples to spike trains:
[2]:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 300
from typing import Union, Optional, Tuple
from rockpool.devices.xylo.syns65302 import AFESimExternal
dt_s = 0.009994
# AFESimExternal
afesim_external = AFESimExternal.from_specification(spike_gen_mode="divisive_norm",
fixed_threshold_vec = None,
rate_scale_factor=63,
low_pass_averaging_window=84e-3,
dn_EPS=32,
dt=dt_s,
)
WARNING:root:`dn_rate_scale_bitshift` = (6, 0) is obtained given the target `rate_scale_factor` = 63, with diff = 0.000000e+00
WARNING:root:`dn_low_pass_bitshift` = 12 is obtained given the target `low_pass_averaging_window` = 0.084, with diff = 1.139200e-04
WARNING:root:`down_sampling_factor` = 488 is obtained given the target `dt` = 0.009994, with diff = -2.400000e-07
AFESimPDM
The diagram below illustrates the difference between AFESimPDM and AFESimExternal.
AFESimPDM includes internally a simulation of a digital microphone model, composed of a sigma-delta modulator, and polyphase lowpass filter to convert the PDM signal to 14-bit quantized data.
This module can be used when debugging the PDM modules on XyloAudio 3.
[3]:
Image("figures/afesimpdm.png")
[3]:

The following transform can convert audio: np.ndarray samples to spike trains:
[4]:
from rockpool.devices.xylo.syns65302 import AFESimPDM
# AFESimPDM
afesim_pdm = AFESimPDM.from_specification(spike_gen_mode="divisive_norm",
fixed_threshold_vec = None,
rate_scale_factor=63,
low_pass_averaging_window=84e-3,
dn_EPS=32,
dt=dt_s,
)
WARNING:root:`dn_rate_scale_bitshift` = (6, 0) is obtained given the target `rate_scale_factor` = 63, with diff = 0.000000e+00
WARNING:root:`dn_low_pass_bitshift` = 12 is obtained given the target `low_pass_averaging_window` = 0.084, with diff = 1.139200e-04
WARNING:root:`down_sampling_factor` = 488 is obtained given the target `dt` = 0.009994, with diff = -2.400000e-07
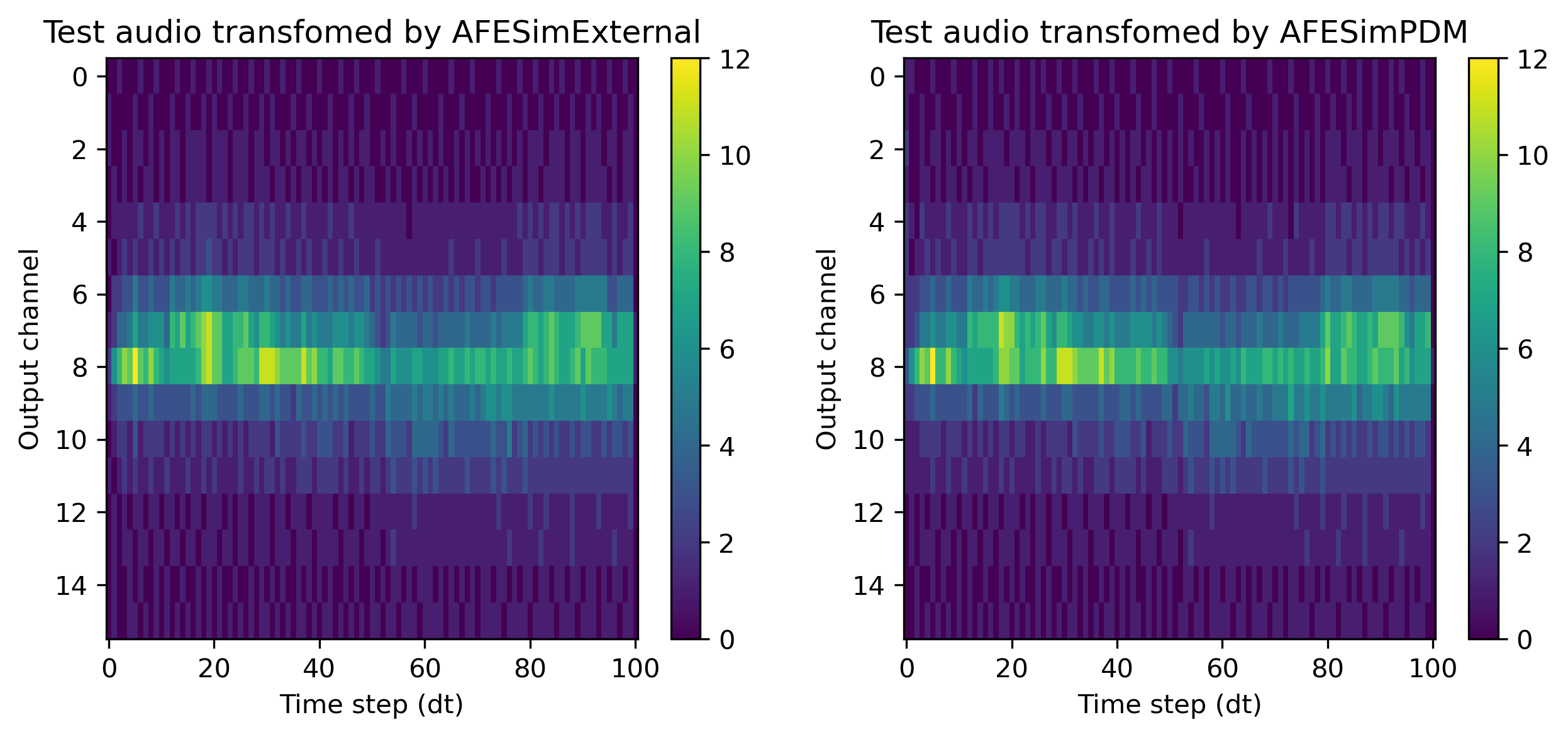
Applying AFESim3 transform
We apply a test audio (a 3 second sample) to both introduced AFESim3 transforms to generate our pre-recorded data
[5]:
!pip install --quiet librosa
import librosa
audio_path = 'audio_sample/scream_sample.wav'
test_sample, sr = librosa.load(audio_path, sr= None)
test_sample = np.expand_dims(test_sample, axis = 0)[0]
[6]:
# Use AFESimExternal Transform
out_external,_,_ = afesim_external((test_sample, sr))
# Use AFESimPDM Transform
out_pdm,_,_ = afesim_pdm((test_sample, sr))
WARNING:2025-04-14 17:53:25,513:jax._src.xla_bridge:969: An NVIDIA GPU may be present on this machine, but a CUDA-enabled jaxlib is not installed. Falling back to cpu.
WARNING:jax._src.xla_bridge:An NVIDIA GPU may be present on this machine, but a CUDA-enabled jaxlib is not installed. Falling back to cpu.
[7]:
plt.figure(figsize=(10,4))
plt.subplot(121); plt.imshow(out_external.T, aspect='auto'); plt.colorbar(); plt.title('Test audio transfomed by AFESimExternal'); plt.xlabel('Time step (dt)'); plt.ylabel('Output channel')
plt.subplot(122); plt.imshow(out_pdm.T, aspect='auto'); plt.colorbar(); plt.title('Test audio transfomed by AFESimPDM'); plt.xlabel('Time step (dt)'); plt.ylabel('Output channel');
[8]:
# - You can now save the transformed data
# np.save('AFESimExternalSample', out_external.T)
print(out_external)
[[2 2 2 ... 1 0 0]
[1 1 2 ... 1 1 1]
[1 2 1 ... 1 0 0]
...
[3 4 6 ... 1 1 1]
[5 4 8 ... 1 0 0]
[2 1 0 ... 0 0 0]]
The output spike train has a dimension of \((N_{steps}, 16)\) where 16 is the number of output channels and \(N_{steps}\) is the duration of the audio in seconds divided by the provided dt of the model.