This page was generated from docs/devices/xylo-a3/xylo-audio3-intro.ipynb.
Interactive online version:
![]()
🐝⚡️ Quick start with Xylo™Audio 3
NOTE: XyloAudio 3 requires
samna==0.39.6or higher
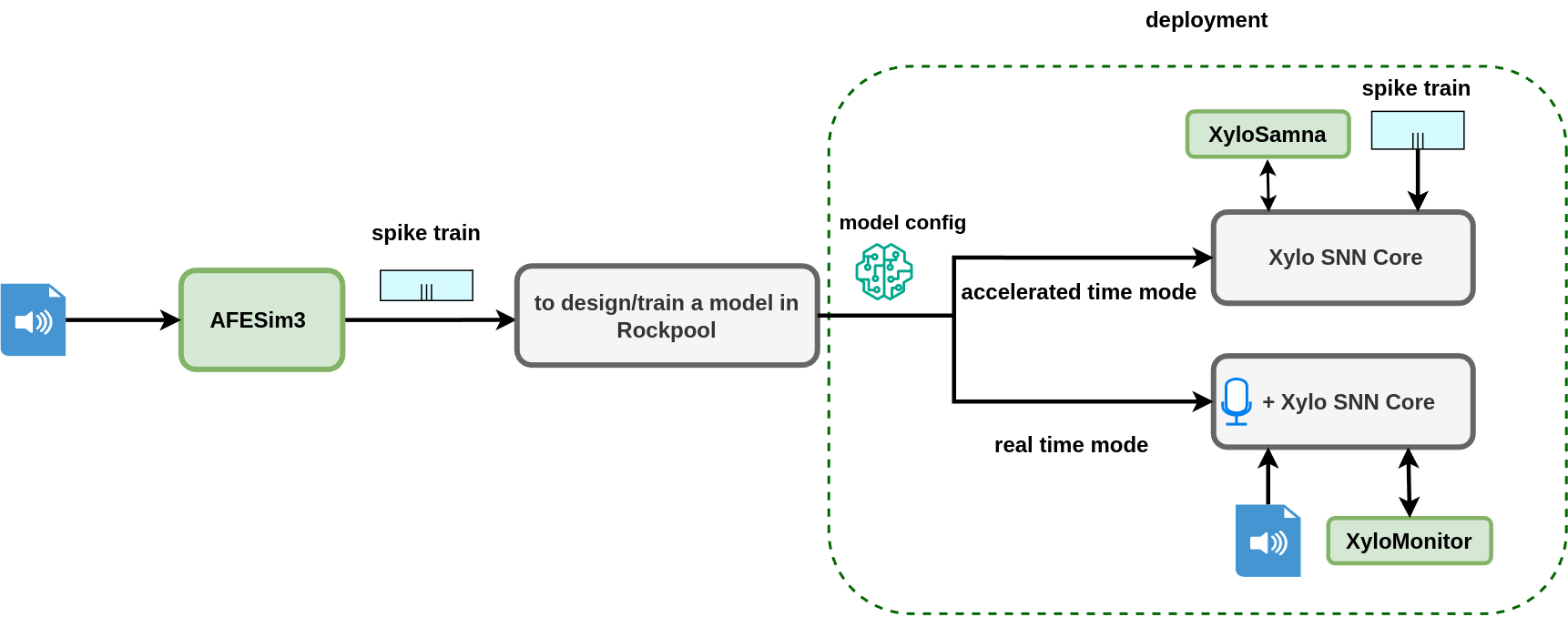
This tutorial will review the steps and tools required to build and train audio applications for deployment on Xylo™Audio 3. A typical pipeline to build and deploy an audio application for Xylo™Audio 3 contains the following steps:
preprocessing: converting audio signals to spike trains
designing and training an SNN model with spike-encoded audio data
deploying the trained model in Xylo™Audio 3 HDK
The following diagram illustrates these steps along with the required tools from Rockpool, highlighted in green:
AFESimPDMandAFESimExternalare tools in Rockpool that simulate the Audio Front End (AFE) of Xylo™Audio 3, used as a preprocessing step to convert audio signals to spike trains.XyloSamnaandXyloMonitorare Rockpool APIs that interface the user and Xylo™Audio 3 HDK. These APIs are designed with user-friendliness in mind, making the interaction with XyloAudio 3 a seamless experience.
Please see: Using AFESim as an audio transform where we elaborated on using AFESimPDM and AFESimExternal as an audio transform to generate spike-encoded samples.
In the In Depth section of the Rockpool documentation at left, you can also see more details about the process of designing and training a model in Rockpool.
Overview of training and deployment flow for Xylo™Audio 3
[1]:
from IPython.display import Image
Image("figures/tools_diagram-150.png")
[1]:
Operation types of XyloAudio 3
XyloAudio 3 HDK has two different operation modes:
Accelerated time
Real-time
Two different deployments can be performed depending on the operation mode. Both require mapping the model’s configuration into the Xylo SNN core and reading the output spikes.
Deployment with live audio from microphone: Trained models can be tested with live audio played to the microphone. This type of deployment runs in Real-time mode.
Deployment by bypassing the microphone path: Trained models can be tested with pre-generated spike-encoded audios. This type of deployment runs in Accelerated time mode.
We use Rockpool’s XyloSamna and XyloMonitor APIs to manage the deployment pipelines in deployment types 1 and 2, respectively..
For more details and an example of each deployment, please see the tutorial Using XyloSamna and XyloMonitor to deploy a model on XyloAudio 3 HDK